Engine

Taken at the RTM Musuem in #Ouddorp
Personal Blog about anything - mostly programming, cooking and random thoughts
Taken at the RTM Musuem in #Ouddorp




WASM has a linear memory to pass data between JavaScript (or any other hosting environment) and WASM. Any data which cannot be represented by WASMs data types (32 and 64bit integers and floats) also has to be passed through this memory.
In JavaScript we can access the WASM memory through a DataView object.
WebAssembly.instantiateStreaming(fetch("lib.wasm"), {}).then(
(obj) => {
const dv = new DataView(obj.instance.exports.memory.buffer)
//...
}
The DataView object allows us to read and write data to the memory. To pass a string to a WASM function we first have to encoded it to bytes and then write these bytes into the memory buffer. setUint8 sets the i-th byte of the memory buffer to the provided value.
// encode string in "program" as utf8 and write to WASM memory
let utf8Encode = new TextEncoder();
const p_data = utf8Encode.encode(program);
for (let i = 0; i < p_data.length; i++) {
dv.setUint8(i, p_data[i])
}
The byte position of the written data serves as the "pointer" to the data, that we have to pass to the WASM function call. As the data was written to the start of the memory it will be 0 in this case.
The function we want to call has this signature (in zig). The example is taken from the chromahack code also used in this article about writing WASM libraries in zig
render_point_2(program: [*]const u8, len: usize, result: [*]f32) void
As we can only pass pointers, not strings directly, we also have to pass the length of our string. Otherwise the called function doesn't knowns how much data has to be read from the linear memory.
The called function calculates a RGB color value. The values are written to the provided result location, therefore we also have to provide a pointer for the result in the call. The first two parameters define the string we pass into the function, start location 0 and length of p_data.length. The third parameter is the result location. This is set to p_data.length as this is the first unused location in our memory, directly after the string.
obj.instance.exports.render_point_2(0, p_data.length, p_data.length);
After the function call we have to retrieve the data from the memory. In this case we know that the function will always write 3 floating point values. Otherwise the function would also need to return the length of the result.
The data is again retrieved throught the DataView object via the getFloat32 function. Note that the address is given as a byte offset and therefore has to be increased by 4 each time (byte size of a float). The second parameter defines the endianness of the read data.
const r = dv.getFloat32(p_data.length + 0, true);
const g = dv.getFloat32(p_data.length + 4, true);
const b = dv.getFloat32(p_data.length + 8, true);
This is written for Zig 0.14.1.
For my chromahack project I've used zig to implement the language. To integrate this into an interactive web app I had to compile it to WASM.
The original function I wanted to export as WASM has this signature:
pub fn render_point(program: []const u8, t: f32, x: f32, y: f32) [3]f32
This was a problem as the WASM target does not support the types []const u8 and [3]f32 as function parameter/return type. Therefore I've created a new function (creatively called render_point_2) to wrap my original implementation:
export fn render_point_2(program: [*]const u8, len: usize, t: f32, x: f32, y: f32, result: [*]f32) void {
const r = render_point(program[0..len], t, x, y);
result[0] = r[0];
result[1] = r[1];
result[2] = r[2];
}
The program is now passed as a pointer to an array + its length. The function no longer has a return value, but writes the result to a provided array address. The caller has to ensure that the array can store 3 floating point values.
Also note the export keyword. I've missed this and spent an hour wondering why my WASM file had no exported function.
To build the WASM file you can either use the zig build-exe command or integrate it into your build.zig file.
The command zig build-exe src/root.zig -target wasm32-freestanding -fno-entry -rdynamic -OReleaseFast will create the WASM file in your project folder.
To build the WASM file via zig build add the following block to your builg.zig file. This will create the file in zig-out/bin. (based on this gist from trasstaloch )
const wasm = b.addExecutable(.{
.name = "lib",
.root_source_file = b.path("src/root.zig"),
.target = b.resolveTargetQuery(std.Target.Query.parse(
.{ .arch_os_abi = "wasm32-freestanding" },
) catch unreachable),
.optimize = optimize,
});
wasm.entry = .disabled;
wasm.rdynamic = true;
b.installArtifact(wasm);
It is also possible to copy further assets into the output directoy, such as your HTML and JavaScript files.
// copy web stuff
b.installBinFile("index.html", "index.html");
b.installBinFile("assets/favicon.png", "favicon.png");
TL;DR: https://chromahack.rerere.org/
![]()
I've created a small programming languages I've been thinking about for a long time. I wanted a programming language that would interpret any string as a valid program and create some visual result out of that. The inspiration was the hacker movie aesthetics, typing furiously on their laptops and bright, colorful patterns flashing over screens.

The language is implemented as a stack based machine. Each character is interpreted as an operation on this stack. For example, a take the top two items from the stack, adds them up and puts the result back. Unassigned symbols are simply ignored.
The stack is initiated with the x and y coordinates of a pixel in an image. (I also put a time value, which is always zero, onto the stack as I want to extend the system for animations in the future).
The program is then executed for each pixel in an [512x512] image. When the program stops (this is guaranteed through the language), the top three items of the stack are interpreted as RGB values.
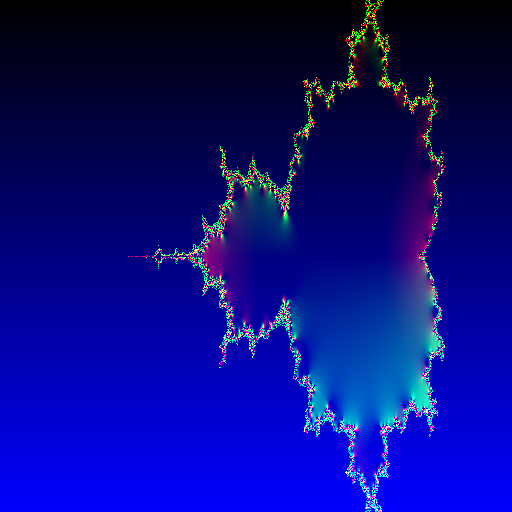
The implementation of the languages itself is rather simple, as it's only a large switch-case statement. As I wasn't sure how fast the interpreter would run when implemented JavaScript I've decided to built it in zig.
The zig program is split into a library and executable. The executable simply wraps the library by invoking the render_point function for each pixel in an image and saving the result to disk.
Usage via the command line was rather tedious. Therefore I've compiled the library to WASM to integrate it into an web app to allow for an interactive workflow.
As rendering a long program might take a few seconds I've split the rendering process into chunks to avoid blocking the UI. Randomizing the order of chunks added a nice hackeresque feel to the process.
To create the layout of the website I used Claude, as this was a part of the process I was not interested in. Everything else is organic, hand-crafted artisanal code.
This was a fun project, which could be implemented within a few programming session. I've struggled a bit generating the WASM file. The zig documentation on this topic is rather slim and many examples are outdated. However, this was the first time I've worked with WASM and in the end it was a simple solution.
In the future I want to implement the animation feature of the language. For this I will also have to increase the performance. I want to try WebGL and SIMD for this. Another interesting topic might be to generate programs through algorithms. I think genetic algorithms could work well with this language as it can be mutated and crossed without concern for validity.
Web Version: https://chromahack.rerere.org/
Source Code: https://codeberg.org/h4kor/chromahack

Sony A6400 with Tamron 18-300mm
Dieses Rezept koche ich zur Zeit sehr häufig in meiner Mittagspause. Es ist schnell und einfach und lässt sich endlos variieren.