Tag: ai
Link:The haters guide to AI
Link: https://www.wheresyoured.at/the-haters-gui/#
Just to get this straight:
- the US banned exports of #AI chips to China in fear of AI supremacy
- They restricted themselves to regulate any AI in the next 10 years
- a few days later #grok became the reincarnation of Hitler himself
If I thought that #AGI was just around the corner I would be really concerned now.
Review: Accelerando by Charles Stross
★★★★★ Accelerando by Charles StrossOne of my favorite science fiction books. It plays in a world shortly before and after the AI singularity. I don't know how to describe it in a review without spoiling the journey, but I found many parallel to technologies and trends which should only emerge years after the publication of Accelerando.
#
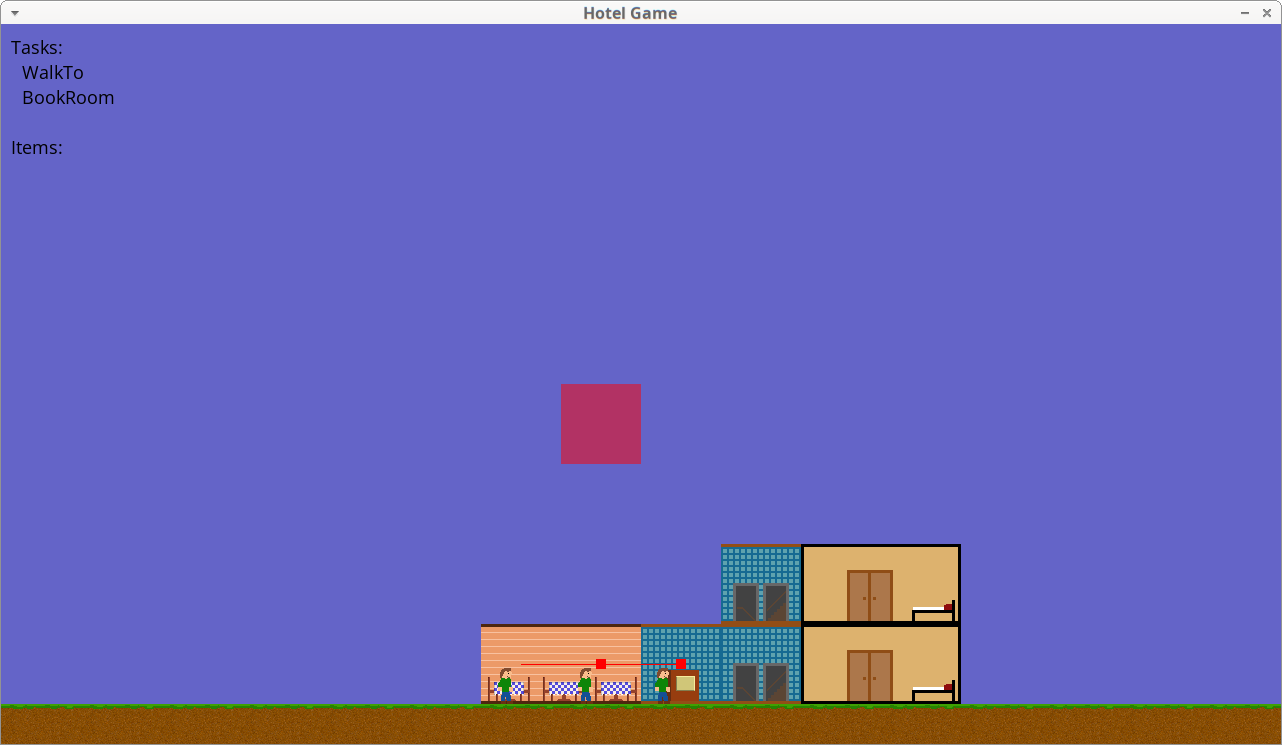
#gamedev progress:
- Implemented A* for navigation
- Started implementing the guests #AI. At the moment they only book a room at the reception and then idle in their room. If no room is available they leave.
- Added further debugging to show path, tasks stack and inventory.
#
The current #AI hype shows the deep disregard of some people for craftsmanship.
They don't say it out loud but I read a lot of variations of "nobody really wants to write code, you want to build application" or "nobody wants to draw, you want to create art" in the last months.
Missed Shot at Artificial General Intelligence
The stated goal of OpenAI is "to ensure that artificial general intelligence benefits all of humanity". With the release of ChatGPT, they might have missed humanity’s only shot at creating an Artificial General Intelligence (AGI).
It's all about data
The performance ("intelligence") of large language models (LLMs) mainly depends on the scale of its training data and the size of the model [1]. To create a better LLM you need to increase its size, and train it on more data. The architecture and configuration of an LLM can almost be neglected in comparison.
However, the intelligence of a model does not grow linearly with its size [1]. There is a diminishing return on increasing the size of LLMs. If you increase the size of model and training set by 10x, you will only get an increase in performance as the previous 10x increase accomplished. This explains why vast amounts of data are required to effectively train large language model.
ChatGPT 3 was trained on 500 billion tokens [2]. There are no official numbers (that I could find) on how much data was used to train ChatGPT 4, but rumors in the AI community state that it was trained on 13 trillion tokens. With this numbers the performance step from 3 to 4 took an 26x increase in data.
The estimation for the size of publicly available, de duplicated data is 320 trillion tokens [4]. This is 24.6x more data than ChatGPT4 was (likely) trained on. If these numbers are correct, the performance of LLMs will only increase as much as it increased from ChatGPT3 to ChatGPT4 before we ran out of data.
I doubt that this will be enough to reach AGI level intelligence.
Poisoned Data
Now you might say "we produce more data every day, models can get better in the future". We could just wait some decades, train new models from time to time and see a gradual increase in performance. And one day we suddenly have an AGI. But the release of ChatGPT created a problem. It poisoned any data collected after November 30, 2022.
The release of ChatGPT was the wet dream of every spammer, bot operator, troll and wannabe influencer. Suddenly you could create seemingly high quality content, indistinguishable from human written text, at virtually zero cost. Ever since the internet gets filled with LLM generated content. And this is a problem for all future trainings.
Models that are trained on their own generations (or data created by other models) start to forget, there performance declines [3]. Therefore you have to avoid training on AI generated content, otherwise the increase in data may decrease your performance. As it is virtually impossible to clean a dataset from AI generated text, any data collected after Nov. 2022 should be avoided. Maybe you can still use a few more months or years of data, but at some point more data will hurt the model more than it helps.
The publicly available data that we got now is all we will get to train an AGI. If we need more data it will have to collected at an exorbitant price to ensure it's not poisoned by AI generated data.
We reached a dead end
The size of current training sets and potentially available data shows that we will not reach AGI levels with the current state of the art approaches. Due to data poisoning we will not get substantially more usable data. Thereby AGI is (currently) not achievable. Opening pandora's box of accessible generative AI may killed our chance of creating an artificial general intelligence.
If we want to build an AGI we will have to do it with the data we have now.
Link: I Will Fucking Piledrive You If You Mention AI Again
Link: https://ludic.mataroa.blog/blog/i-will-fucking-piledrive-you-if-you-mention-ai-again/Great rant about #AI
Link:Situational Awareness - The Decade Ahead
Link: https://situational-awareness.ai/Thesis arguing that #AGI will be reached in the next decade. Have not yet read the full text.
Problems I see with the argumentation so far:
The Data Wall
The data wall is an (hard) open problem. Larger models either will need massively more data or be orders of magnitude more efficient with the given data.
More data is not available at that scale. The latest models are already trained on virtually the entire internet. They argue that a strategy similar to AlphaGo, where the model created it's own training data by playing against itself, could be deploy for #GenAI. I find this implausible as generating intelligent text beneficial in trying already requires a more capable AI.
Similarily being more efficient with data is still an open problem, but I don't know enough about this to evaluate how likely this is to happen.
Additionally, going forward, any new datasets will be poisoned by AI output as they are already used on massive scale to create "content". Research suggests that training on these data degrades the performance of models.
Large Scale Computing
Even is the data wall is broken scaling the models will need massive computing power consuming ever more resources and energy. This will only be tolerated by the general public as long as this is overall beneficial to them. There are already industries (mainly creative ones) being massively disrupted by the current generation of GenAI. Philosophy Tube in Here's What Ethical AI Really Means, shows how strikes and collective action can be tools to prevent the development of more powerful AI systems.
#
Unfinished thought:
People argue that AI will replace all these workers as there work is easily automated. Simultaneously they will not be replaced as there is so much more to their job than the thinks they type into their keyboard.
There is a disconnect where people judge the work of others only by the observable output while recognizing that there own work is worth more than the output visible by others.
Similar to surveys about UBI (universal basic income):
- 80% of people would still work with an UBI
- 80% of people think their neighbors would stop working with an UBI