Link:Warranty Void If Regenerated
Link: https://nearzero.software/p/warranty-void-if-regeneratedWonderful short story about the world of #ai generated #code
Personal Blog about anything - mostly programming, cooking and random thoughts
Wonderful short story about the world of #ai generated #code
Just to get this straight:
If I thought that #AGI was just around the corner I would be really concerned now.
One of my favorite science fiction books. It plays in a world shortly before and after the AI singularity. I don't know how to describe it in a review without spoiling the journey, but I found many parallel to technologies and trends which should only emerge years after the publication of Accelerando.
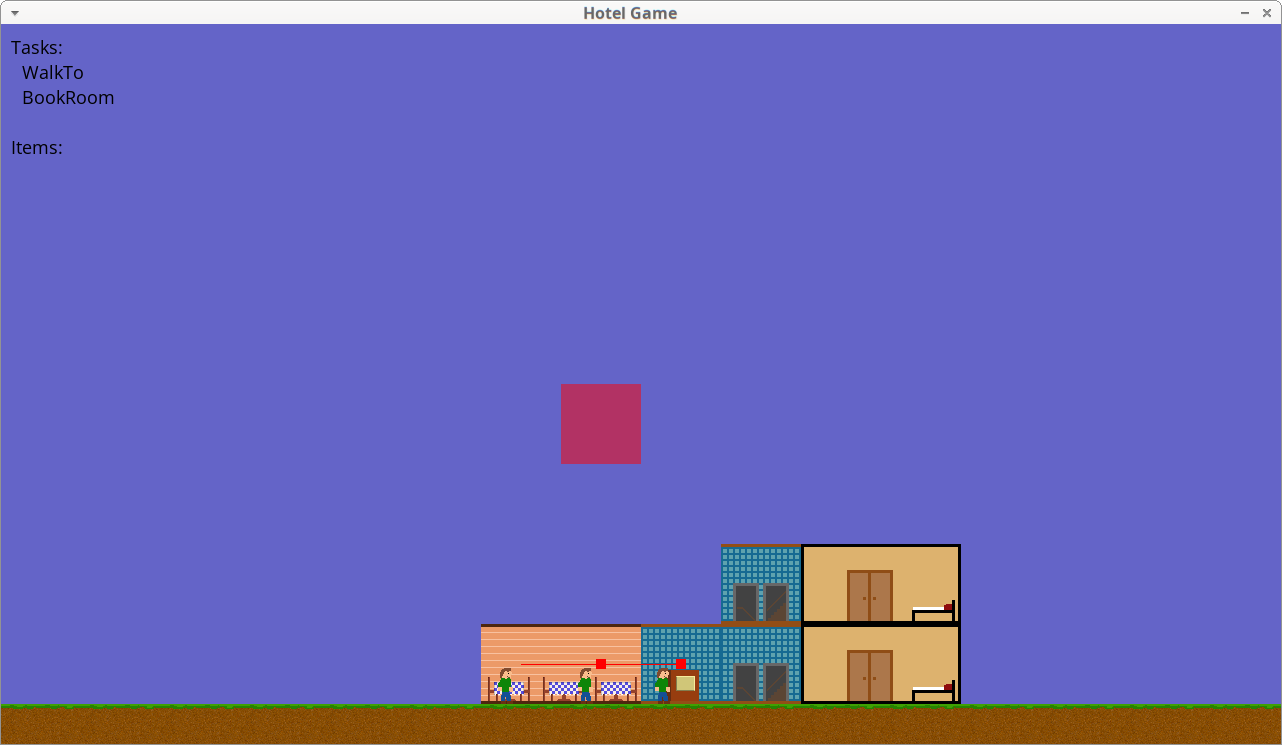
#gamedev progress:
The current #AI hype shows the deep disregard of some people for craftsmanship.
They don't say it out loud but I read a lot of variations of "nobody really wants to write code, you want to build application" or "nobody wants to draw, you want to create art" in the last months.
The stated goal of OpenAI is "to ensure that artificial general intelligence benefits all of humanity". With the release of ChatGPT, they might have missed humanity’s only shot at creating an Artificial General Intelligence (AGI).
The performance ("intelligence") of large language models (LLMs) mainly depends on the scale of its training data and the size of the model [1]. To create a better LLM you need to increase its size, and train it on more data. The architecture and configuration of an LLM can almost be neglected in comparison.
However, the intelligence of a model does not grow linearly with its size [1]. There is a diminishing return on increasing the size of LLMs. If you increase the size of model and training set by 10x, you will only get an increase in performance as the previous 10x increase accomplished. This explains why vast amounts of data are required to effectively train large language model.
ChatGPT 3 was trained on 500 billion tokens [2]. There are no official numbers (that I could find) on how much data was used to train ChatGPT 4, but rumors in the AI community state that it was trained on 13 trillion tokens. With this numbers the performance step from 3 to 4 took an 26x increase in data.
The estimation for the size of publicly available, de duplicated data is 320 trillion tokens [4]. This is 24.6x more data than ChatGPT4 was (likely) trained on. If these numbers are correct, the performance of LLMs will only increase as much as it increased from ChatGPT3 to ChatGPT4 before we ran out of data.
I doubt that this will be enough to reach AGI level intelligence.
Now you might say "we produce more data every day, models can get better in the future". We could just wait some decades, train new models from time to time and see a gradual increase in performance. And one day we suddenly have an AGI. But the release of ChatGPT created a problem. It poisoned any data collected after November 30, 2022.
The release of ChatGPT was the wet dream of every spammer, bot operator, troll and wannabe influencer. Suddenly you could create seemingly high quality content, indistinguishable from human written text, at virtually zero cost. Ever since the internet gets filled with LLM generated content. And this is a problem for all future trainings.
Models that are trained on their own generations (or data created by other models) start to forget, there performance declines [3]. Therefore you have to avoid training on AI generated content, otherwise the increase in data may decrease your performance. As it is virtually impossible to clean a dataset from AI generated text, any data collected after Nov. 2022 should be avoided. Maybe you can still use a few more months or years of data, but at some point more data will hurt the model more than it helps.
The publicly available data that we got now is all we will get to train an AGI. If we need more data it will have to collected at an exorbitant price to ensure it's not poisoned by AI generated data.
The size of current training sets and potentially available data shows that we will not reach AGI levels with the current state of the art approaches. Due to data poisoning we will not get substantially more usable data. Thereby AGI is (currently) not achievable. Opening pandora's box of accessible generative AI may killed our chance of creating an artificial general intelligence.
If we want to build an AGI we will have to do it with the data we have now.
Great rant about #AI