Be prepared. In my case the material was sent out a week beforehand. Use the time to setup your machine(s) and code base so you can start directly.
Do research on the topic. I've not looked into state of the art algorithms for the problem beforehand. This cost me a lot of time in the Hackathon, to understand the algorithm we used.
Have compute resources ready. I could have used 2 further machines, but forgot to setup ssh, Teamviewer or any other remote control on them.
Do whatever you know best. Some of my team members had far more experience on the topic than me. I've tried to follow there example, which wasn't successful. I think I would have been more successful using more basic approaches (which I have enough knowledge about) than trying to follow the "state of the art" approach. At the end I've tried to support them as best as I could (mostly doing evaluations).
Push for more organization. We quickly came to the conclusion that only 1 or 2 approaches (transfer learning on common models) would be feasible in the short time of a hackathon. This led to us being rather unorganized. Everybody tried to get the models running as fast as possible and tweaking them the rest of the time. I think we could have produced more insight on the topic with regular "stand ups".
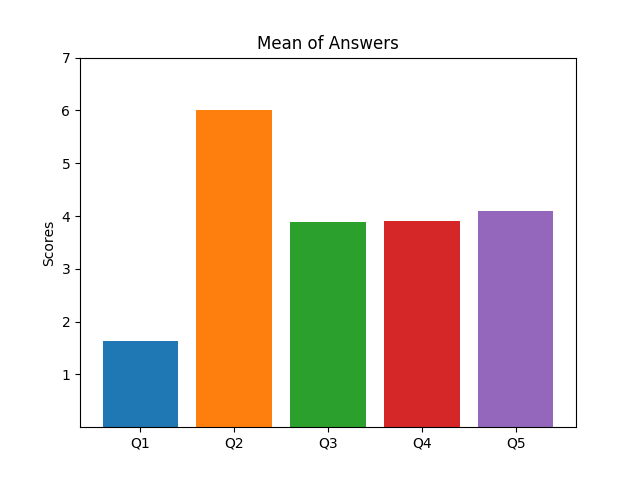
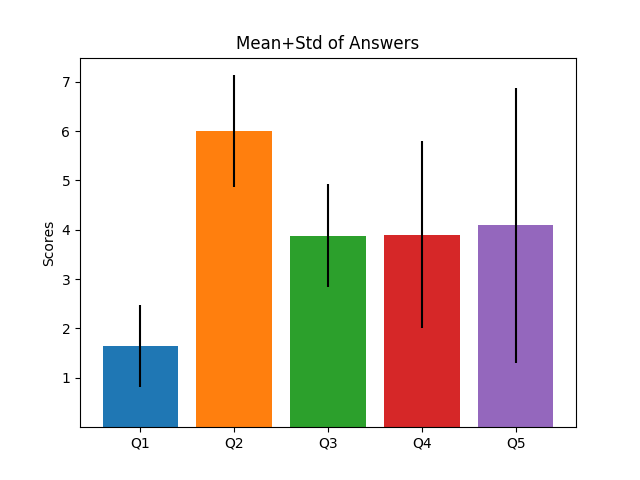
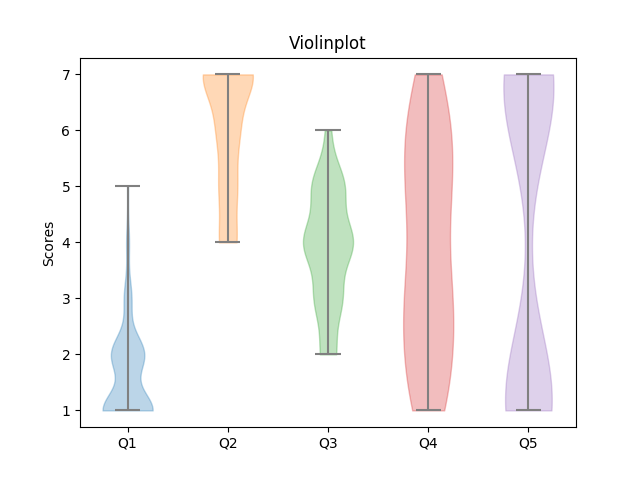
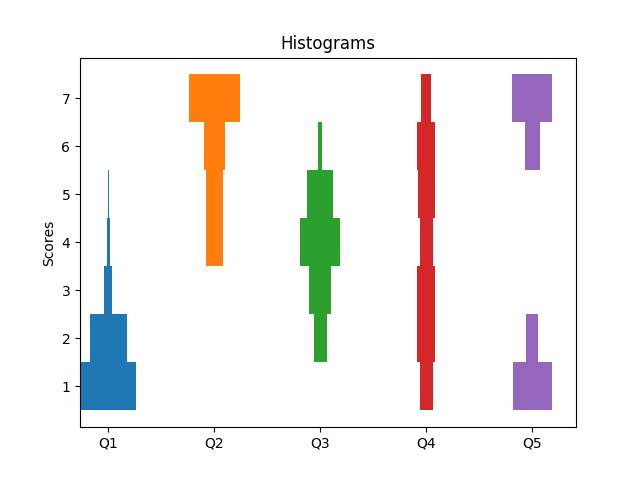
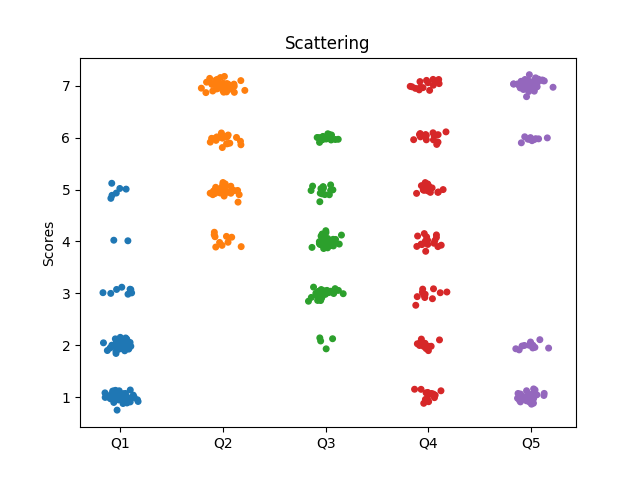
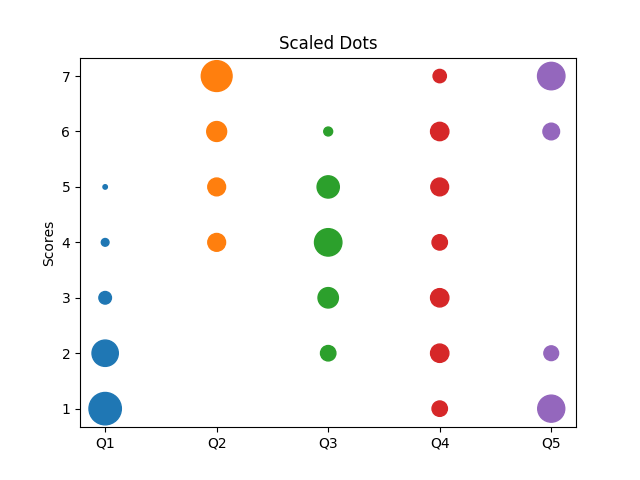
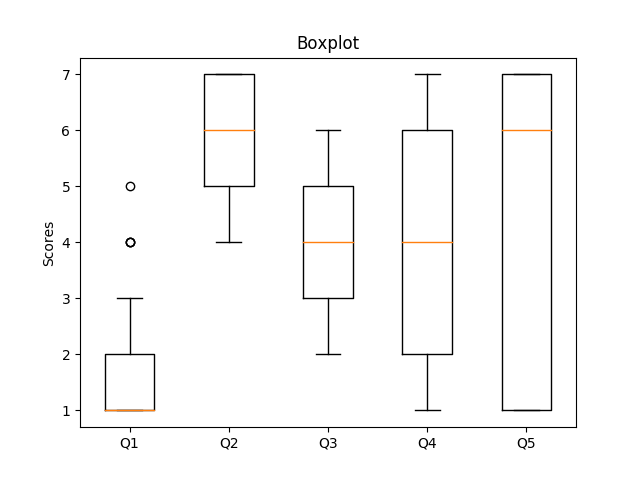
I'm currently helping to evaluating a large market research survey, which ueses Likert Scales. To visualize the data I've tried several plots. The plots below where created with artificially created data to expose the strengths and weaknesses of different plot types.