Zaunkönig

Personal Blog about anything - mostly programming, cooking and random thoughts







One of my favorite science fiction books. It plays in a world shortly before and after the AI singularity. I don't know how to describe it in a review without spoiling the journey, but I found many parallel to technologies and trends which should only emerge years after the publication of Accelerando.
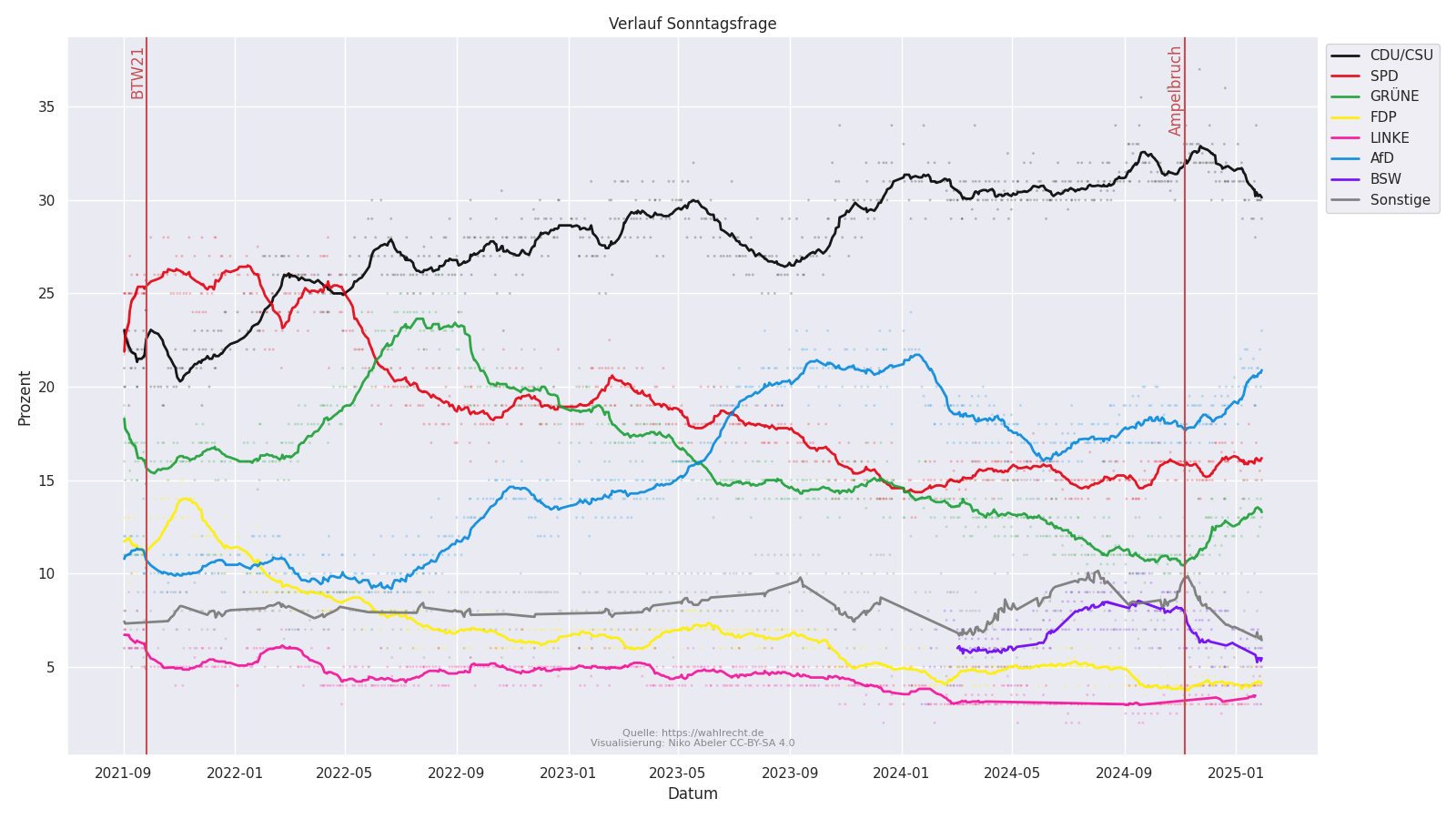
Mit der anstehenden Bundestagswahl 2025 habe ich mich mal einen Abend hingesetzt um den Verlauf der Umfrageergebnisse zu visualisieren. Die Daten stammen von https://wahlrecht.de.
Punkte zeigen einzelne Erhebungen, die Linie ist der Durchschnitt der letzten 14 Befragungen. Die Daten aller Institute wurde genutzt. Bei der "Gesellschaft für Markt- und Sozialforschung" habe ich die Sonstigen und BSW verworfen, da diese zusammen in einer Spalte aufgelistet wurden.